Projects
The portfolio includes all the works that are somehow related to the /DH.arc centre, including projects born and maintained at the /DH.arc centre, projects inherited from prior centres (e.g. Multimedia Centre CRR-MM), or projects born in a different context that are lead by /DH.arc members.
Projects at /DH.arc

ArCo - The Italian Cultural Heritage Knowledge Graph
Keywords: Arts, Creative Industries, Knowledge Graphs, Semantic Web, Linked Open Data
Description: ArCo is a joint project by the Italian Ministry of Cultural Heritage's (MiBAC) agency ICCD (Istituto Centrale per il Catalogo e la Documentazione), and the Semantic Technology Lab (STLab) of ISTC-CNR, a partner of DHARC (some STLab researchers are hosted by the FICLIT Department). ArCo, based on ICCD norms for the description of cultural heritage, has designed an ontology network, and a knowledge graph of 800,000 Italian cultural entities, with relations to artists, places, institutions, techniques, etc.
Researchers: Valentina Presutti (CNR project coordinator). Valentina Carriero, Andrea Nuzzolese (STLab), Aldo Gangemi, open to DHDK students for internships
Funded by: ICCD
Release: 2018 (alpha); 2019 (official)
Status: Ongoing, first stable release available

ARTchives - The Inventory of Art Historians’ Archives
Keywords: Arts, Creative industries, Knowledge organization, Data collection, Knowledge Discovery
Description: The inventory of Art Historians’ Archives aims at gathering, describing and consuming information on archives produced by notable art historians spread around the world. The objective is to provide a flexible service for collecting data on art history related topics and serve accurate Linked Open Data. A web application leveraging so created data will provide scholars with new expressive means for discovering data.
Researchers: Marilena Daquino, Francesca Tomasi, Francesca Mambelli
Funded by: Federico Zeri Foundation
Release: 2019 (Beta version)
Status: Ongoing

CATARSI
Keywords: automatic analysis of scholarly documents, web-based interfaces, workflow definition and execution
Description: the project aims at analysing existing tools for automatic text analysis, so as to develop a prototypical Web-based application for mashing up these tools to create execution workflows by means of an intuitive Web interface.
Researchers: Ivan Heibi, Silvio Peroni
External collaborators: Paolo Ferri (University of Bologna, Italy), Luca Pareschi (University of Bologna, Italy)
Funded by: University of Bologna
Status: Ongoing
CLEF. Crowdsourcing Linked Open Entities via web Forms
Keywords: Linked Open Data, Crowdsourcing,
Description: CLEF is a LOD-native cataloguing system developed to facilitate data collection and interlinking with external datasets (e.g. Wikidata). Like a few well-known open source software solutions for online cataloguing (e.g. Omeka, ResearchSpace, Semantic Wikibase) CLEF allows users to create and manage online catalogues of cultural heritage resources and to serve data as Linked Open Data.The idea is to have a lightweight software, easy to install and customise. CLEF is based on a python framework (webpy) and comes with an instance of Blazegraph triplestore.
Researchers: Marilena Daquino, Sebastiano Giacomini
Funded by: Polifonia H2020
Release: April 2022
Status: Ongoing

DH.ARC/ Vocabularies
Keywords: FAIR, Semantic Artefacts, Semantic Web
Description: The /DH.arc Vocabularies repository provides access to semantic artefacts, such as controlled vocabularies and ontologies, created by DH.ARC/ and related entities and researchers. Semantic artefacts hold a special importance as products of research in that they are both key to achieving FAIR-ness in the data being produced and are themselves research objects that should be FAIR, yet the latter is often less considered than the former. As such, the primary goal of the repository is to make it easier for semantic artefacts produced by /DH.arc to be FAIR and thus more accessible and visible both within and outside of research communities.
The repository was developed as part of the KNOT pilot project and runs on Skosmos, a web based open-source ontology browser developed and released by the team at the National Library of Finland, which uses SKOS as the underlying data model. One notable difference with other existing Skosmos installations is that this repository makes ontologies originally written in OWL available by overlaying OWL and SKOS.
Researchers: Laurent Fintoni, Francesca Tomasi
Release: 2025
Status: Ongoing

DHDKey!
Keywords: projects, dataset, DHDK classes
Description: DHDKey! (Digital Humanitites and Digital Knowledge Educational Yearbook) is an online database devoted to the collection and publication of metadata of all projects developed by students of the master course of Digital Humanitites and Digital Knowledge at the University of Bologna. DHDKey! is a platform developed and managed by students for students. The idea behind DHDKey! is not only to organize all the projects carried out during the course in a historical collection, but also to provide all students of the course with their own academic portfolio. All students of the Digital Humanities and Digital Knowledge course can upload their project data through the appropriate form provided by the website.
Researchers: Fabio Mariani (DHDK graduated student)
Collaborators: Silvio Peroni, Francesca Tomasi
Funded by: DH.ARC, University of Bologna
Release: 2020
Status: Ongoing
Digital Library (FICLIT)
Keywords: Omeka, IIIF, Mirador, Cultural Heritage ontologies, Metadata, Archival founds and collections
Description: The digital version (data and metadata) of cultural archives and collection held and maintained by the Department of Classical Philology and Italian Studies.
Researchers: DH.ARC members
Collaborator: Francesca Giovannetti (DH PhD)
Funded by: FICLIT Dipartimento di Eccellenza (2018-2022), University of Bologna
Release: 2019 (first draft); 2022 (second release)
Status: Ongoing
DocuDipity
Keywords: Document visualization, information interfaces and presentation, reading patterns
Description: DocuDipity is an interactive Web-based tool to support the exploration and analysis of heterogeneous document collections. It supports scholars by combining a sequential reading interface with alternative visualizations such as SunBurst and tree-based views.
Researchers: Francesco Poggi, Angelo Di Iorio, Silvio Peroni, Fabio Vitali, Paolo Ciancarini
Funded by: University of Bologna
Status: Ongoing

Edizione nazionale delle opere di Aldo Moro
Keywords: Knowledge organization, Text encoding, Critical digital edition
Description: the project of the digital edition of the National Edition of Aldo Moro’s Works intends to implement a new model workflow for national editions according to the best practices and international standards for critical digital editions. The annotations encoded in RDF/A focus on inter and intra-textual aspects such as people, organizations and places and aim at providing a new insight of the great Italian statistician. Showcase website.
Researchers: Sebastian Barzaghi, Francesco Paolucci, Francesca Tomasi, Fabio Vitali, Aldo Gangemi
Collaborators: Giulia Massimino, Ariele Santelli (DHDK graduated students)
Funded by: Edizione nazionale delle opere di Aldo Moro (MIBAC)
Announcement: Unibo Magazine
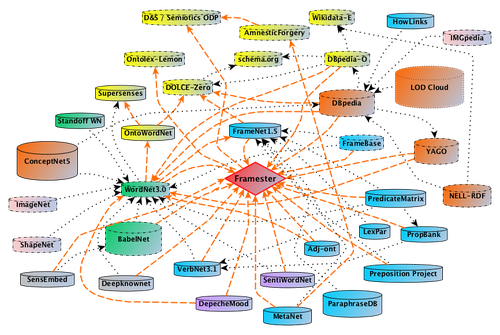
Framester: a large-scale factual-linguistic knowledge graph based on frame semantics
Keywords: Semantic Interoperability, Lexicons, Frame Semantics, Knowledge Graphs, Semantic Web, Linked Open Data
Description: Framester is large factual-linguistic knowledge graph, based on a formalisation of Fillmore's frame semantics, and hosted on GitHub. It offers accurate alignments and formal representation for lexical resources such as FrameNet, WordNet, VerbNet, BabelNet, etc., as well as alignments to factual graphs such as DBpedia and YAGO, and foundational ontologies such as DOLCE. Framester creates a highly connected knowledge graph, enabling full-fledged OWL querying and reasoning, and fostering large-scale semantic interoperability. It has a dedicated SPARQL Endpoint, including a RESTful API. Originally designed by the RCLN group at LIPN, Paris Nord University, it is currently maintained jointly by CNR's STLab and DHARC.
Researchers: Aldo Gangemi (coordinator), Mehwish Alam, Luigi Asprino, Valentina Presutti (CNR), open to DHDK students for internships.
Funded by: MARIO Project (EU H2020 programme), EFL LabEx (French Ministry of Research)
Release: 2016
Status: Ongoing, stable release available

FRED: state-of-the-art knowledge graph extraction from text
Keywords: Knowledge Extraction, Natural Language Processing, Frame Semantics, Knowledge Graphs, Linked Open Data
Description: FRED is a state-of-the-art tool for automatically extracting knowledge graphs from English (other languages via automated translation) text, and link them to existing knowledge. It can be considered a machine reader for the Semantic Web: it is able to parse natural language text, and transform it to linked data. It is implemented in Python, and available as REST service as well as a Python library suite [fredlib]. FRED background theories include: Combinatory Categorial Grammar, Discourse Representation Theory, Frame Semantics, and Ontology Design Patterns. FRED leverages Natural Language Processing components for performing Named Entity Resolution (using Stanbol and TagMe), Coreference Resolution (using CoreNLP), and Word Sense Disambiguation to DBpedia, schema.org, WordNet, VerbNet, and FrameNet. All FRED graphs include textual annotations and represent textual segmentation, expressed by means of EARMARK and NIF. Originally developed in the EU FP7 IKS project by CNR's STLab, it has been later improved also in the RCLN group at LIPN, Paris Nord University, and is currently maintained jointly by STLab and DHARC. FRED has been extended for Aspect-based Sentiment Analysis (Sentilo), type induction (Tìpalo), knowledge reconciliation (Mergilo), and synthetic relation extraction (Legalo).
Researchers: Aldo Gangemi (coordinator), Mehwish Alam, Luigi Asprino, Andrea Nuzzolese, Valentina Presutti (CNR), and Diego Reforgiato Recupero (University of Cagliari). Open to DHDK students for internships.
Funded by: FP7 IKS Project
Release: 2012; 2015; 2017
Status: Ongoing, stable release available as a web service

KNOT. Rethinking Scholarly Digital Objects As Cultural Heritage
Keywords: Scholarly Digital Objects, Digital Cultural Heritage, Italian universities
Description: KNOT is a three-year pilot (2023-2025) tasked with investigating ways to integrate the digital cultural heritage of Italian universities into the national infrastructure being built by the Central Institute for the Digitization of Cultural Heritage (ICDP) - Digital Library.
For years now academic research has operated in a primarily digital space, with digital tools playing an increasingly important role in both the activity of research and the production of results as digital-born and/or digitized objects. As a result of this, universities find themselves already in possession of a multifaceted and interesting, and so far unexplored, example of Digital Cultural Heritage in the form of digital objects created by academic research projects. These scholarly digital objects are the focus of investigation of the KNOT project with the goal to explore ways to describe and valorize them within the context of I.PaC, the national infrastructure being built by the ICDP.
The project produced a data model for the description of Scholarly Digital Objects, a catalogue (which runs on CLEF) of over 100 digital objects and projects associated with Italian universities, a taxonomy of Scholarly Digital Objects and a thesaurus of digital technologies, and a repository for semantic artefacts (DH.ARC/ Vocabularies).
Researchers: Laurent Fintoni, Marilena Daquino, Francesca Tomasi
Funded by: Ministry of Culture
Release: 2024, 2025
Status: Finished

Leggo Manzoni
Keywords: Digital Philology, Italian Literature, Alessandro Manzoni, I Promessi Sposi
Description: Leggo Manzoni is a platform that makes it possible to read, in parallel with the text, in complete or partial form, forty commentaries on The Betrothed, comparing them with the text of the novel or with each other. Also available on the portal is the digital version of the 1840 illustrated edition: VEDO MANZONI, which can be queried using search keys: Chapter, Author, Theme, Character, Place, Function, Subject.
Researchers: Paola Italia, Francesca Tomasi, Maria Levchenko, Giulia Menna, Matilde Passafaro, Beatrice Nava, Sara Obbiso, Ersilia Russo
Collaborators: Martina Dello Buono (PhD)
Funded by: DH.ARC, University of Bologna; PRIN Manzoni 2017
Current release: 2024
Status: Ongoing

LIFT - Linked data from TEI
Keywords: Digital edition, Knowledge graph, Linked Open Data, TEI, Transformation
Description: LIFT is a Python-based tool for transforming your TEI XML edition into a knowledge graph, ready for publication as linked open data on the web. LIFT comes with a thorough documentation, designed to help you understand and reuse the methodology and technology behind the tool.
Researchers: Francesca Giovannetti, Francesca Tomasi
Funded by: GARR
Release: 2020
Status: Ongoing. First stable release available

mAuth - mining Authoritativeness in Art History
Keywords: Arts and Photography, Authoritativeness, Information Retrieval
Description: mAuth is a tool for art historians, data collection managers, and curious, who want to collect information - historians' opinions, motivations, bibliographic references, and images - about the history of authorship attributions related to artworks of the Modern Art (15-16th centuries). It is based on a semantic crawler that harvests authorship attributions in the Web of Data and returns the list of contradictory statements sorted by their authoritativeness.
Researchers: Marilena Daquino, Francesca Tomasi
Release: 2018
Status: Closed

MELODY. Make mE a Linked Open Data storY
Keywords: Data visualization, Linked Open Data
Description: MELODY is an online platform for creating web-ready data stories (i.e. web articles including curated text content and charts) basedon Linked Open Data. The platform offers a user-friendly interface to query online data sources, and populate a canvas with text, counters, charts, interactive text searches, maps and more.
Researchers: Giulia Renda, Marilena Daquino
Funded by: Polifonia H2020
Release: 2022
Status: Ongoing
Keywords: Semantic Collection, Linked Open Data, Mythologiae, Canonical Citations, Digital Hermeneutics
Description: The project presents Mythologiae digital collection revalorisation into Linked Open Data format, fostering Semantic Web technologies. It focuses over the formal representation of experts’ analysis when associating artworks (and their interpretation) to literary sources. Additionally, the layered approach to knowledge organisation allows to represent artworks descriptive metadata along with interpretations contextual information.
Researchers: Valentina Pasqual, Francesca Tomasi
Funded by: IDEHA - Innovazioni per l'elaborazione dei dati nel settore del patrimonio culturale
Release: 2021
Status: Ongoing

musoW 2.0: the online catalogue of Music Heritage on the web
Keywords: Linked Open Data, Music Heritage, Crowdsourcing
Description: musoW 2.0 is the online registry of music resources on the web. It is a crowdsourced, manually curated, Linked Open Dataset including more than 500 digital collections relevant to musicologists, music historians, journalists and librarians. musoW is published using CLEF, a LOD-native cataloguing system developed by /DH.arc to facilitate data collection and interlinking with external datasets (e.g. Wikidata).
Researcher: Marilena Daquino
Funded by: Polifonia H2020
Release: December 2021
Status: Ongoing

ODI: uno studio su Il Castello dei Destini incrociati di Italo Calvino
Keywords: Ontology, Italo Calvino, Combinatory Literarure, Semantic Web, Knowledge Base, Web-app
Description: ODI investigates the “macchina narrativa combinatoria” of Il Castello dei Destini incrociati by Italo Calvino using Semantic Web technologies to formalize and analyze textual and iconographical aspects that concern narrative and compositional structures, plot concepts and character roles in all the stories. Data has been analyzed in the light of three main aspects: the semantics conveyed by the tarot cards, the text structure and the relations between cards. ODI (Ontologia dei Destini incrociati di Italo Calvino) and its corresponding Knowledge Base (BACODI, Base di Conoscenza dell’Ontologia dei Destini incrociati di Italo Calvino) can be accessed through a web interface with the goal of surpassing the traditional presentation of digital editions.
Researcher: Enrica Bruno, Valentina Pasqual, Francesca Tomasi
Release: 2023
Status: Ongoing

OpenCitations Enhancement Project
Keywords: infrastructure, open citation data, interfaces for citation data
Description: The project aimed at making the datasets made available by OpenCitations more useful to the academic community both by significantly expanding the volume of citation data held within them, and by developing novel data visualizations and query services over the stored data.
Researchers: Marilena Daquino, Ivan Heibi, Silvio Peroni
External collaborators:David Shotton (University of Oxford, UK)
Funded by: Alfred P. Sloan Foundation
Status: Finished

Open Biomedical Citations in Context Corpus
Keywords: in-text reference pointers, open citation data, citation contexts
Description: The project aims at making the OpenCitations Corpus (OCC) more useful to the academic community by significantly expanding the kinds of citation data held within the Corpus, so as to provide data for each individual in-text reference and its semantic context, making it possible to distinguish references that are cited only once from those that are cited multiple times, to see which references are cited together (e.g. in the same sentence), to determine in which section of the article references are cited (e.g. Introduction, Methods), and, potentially, to retrieve the function of the citation.
Researchers: Ivan Heibi, Silvio Peroni
External collaborators: Vincent Larivière (Université de Montréal, Canada), David Shotton (University of Oxford, UK), Ludo Waltman (Leiden University, The Netherlands)
Funded by: Wellcome Trust
Status: About to start
Philoeditor
Keywords: Digital Philology, Italian Literature, Authorial Philology, Alessandro Manzoni, I Promessi Sposi, Collodi, Le avventure di Pinocchio
Description: PHILOEDITOR is a digital platform which allows to read texts that present multiple authorial drafts, representing the different versions and categories of variants marked by the editor. Texts currently available: I Promessi Sposi by Alessandro Manzoni (1827/1840) and Le avventure di Pinocchio by Carlo Collodi (1883/1890).
Researchers: Paola Italia, Francesca Tomasi, Fabio Vitali, Claudia Bonsi, Angelo Di Iorio, Teresa Gargano, Ersilia Russo
Collaborators: Martina Dello Buono (DHDK graduated student), Guglielmo Gualerzi (DISI student)
Funded by: DH.ARC, University of Bologna
Current release: 2020
Status: Ongoing
Ragu - Reti e Archivi del Gusto
Keywords: digital collection, cookbooks, data visualization
Description: Ragu is a project devoted to collect, digitise and make available online images and data about Italian family cookbooks written from the IIWW. /DH.arc helped scholars of the project to collect, clean, manage, and serve data in a semi-automated way, so as to populate and keep up to date the website dedicated to the data exploration.
Researchers: Mila Fumini, Giulia Manganelli, Giulia Renda, Marilena Daquino
Funded by: DH.arc, University of Bologna
Release: 2022 (pilot)
Status: Closed

Semantic Digital Edition of Paolo Bufalini’s notebook
Keywords: Contemporary literature, Knowledge organization, Intertextuality, Intratextuality, Text encoding, Semantic Digital Edition
Description: The Semantic Digital Edition of Paolo Bufalini’s notebook aims at creating a scholarly edition enhanced by Semantic Web technologies. The digital edition, initially encoded in TEI/XML, focuses on inter and intra-textuality aspects. The RDF version of the edition aims at reconstruct the broad library owned by the scholar and enrich available information with data extracted from external sources. Current github repository.
Researchers: Francesca Giovannetti, Marilena Daquino, Francesca Tomasi
Collaborator: Martina Dello Buono (DHDK graduated student)
Release: 2018 (next release 2020)
Status: Ongoing

Semantic Digital Edition of Vespasiano da Bisticci’s Letters
Keywords: Renaissance, Creative industries, Semantic Digital Edition
Description: The Semantic Digital Edition of Vespasiano da Bisticci’s letters aims at highlighting the network of relations between intellectuals, copists, and customers that lead to the creation of a number of manuscripts during the Renaissance period. The edition focuses on such aspects and the semantic version of the edition aims at highlighting aspects related to the evolution of creative industries over time. It's possibile to browse two different version: Semantic Digital Edition (version 2.0); Knowledge Site (version 3.0); and have access to Documentation and Visualization (version 3.0 reproducibility).
Researchers: Francesca Tomasi, Marilena Daquino
Collaborator: Sebastian Barzaghi (DHDK graduated student)
Release: version 2.0, 2013; version 3.0, 2020
Status: Ongoing

Śivadharma database
Keywords: Digital Edition, Sanskrit sources, Linked Open Data, Semantic web, Data visualization
Description: Śivadharma database project aims at developing a web application based on Semantic web and LOD technologies to catalogue, browse and preserve the Sanskrit textual sources of Śivadharma corpus, specifically their metadata, transcriptions and translations in English, Scholarly Digital Editions, and related multimedia materials, as the manuscript witnesses facsimiles. In addition, data visualization tools will be implied to enhance the user experience handling with LOD data. Current github repository.
Researchers: Martina Dello Buono, Francesca Tomasi
Funded by: Alma Mater Studiorum - University of Bologna, Università degli Studi di Napoli L'Orientale
Release: 2024
Status: Ongoing

SPICE
Keywords: Social cohesion, Participation, and Inclusion through Cultural Engagement
Description: "The overall aim of the project is to foster diverse participation in the heritage domain through a process of ""citizen curation"". Citizens will be supported to: develop their own personal interpretations of cultural objects; work together to present their collective view of life through culture and heritage; and gain an appreciation of alternative cultural viewpoints.
Researchers (PI): Aldo Gangemi, Silvio Peroni
Unibo Collaborators: Stefano De Giorgis, Marilena Daquino, Delfina Sol Martinez Pandiani, Sofia Pescarin, Bruno Sartini, Francesca Tomasi
Team: The project brings together 13 partners from 7 countries. The consortium comprises: three SMEs from the visitor guide (GVAM), mobile game (PadaOne) and data mining (CELI) sectors; four heritage institutions (Design Museum Helsinki, Irish Museum of Modern Art, Gallery of Modern Art Turin, Hecht Museum); and seven research centres (Bologna, Aalto, Aalborg, OU, UCM, Turin, Haifa) with expertise in codesign, museology, HCI, Linked Data, narratology, ontologies, visualisation and user modelling
Funded by: H2020
Dates: 2020-2023
Status: Closed
SSE - Smart Structured Editor
Keywords: Templates, Authoring, Collaborative Editing, Technical documentation, Versioning
Description: SSE is a Web platform that allows users users to easily (i) produce structured content enriched with some metadata to easy the document tracking and exploration and (ii) share content fragments via templating. Originally developed for writing technical documentation, the system is flexible and extensible to other domains and content types.
Researchers: Fabio Vitali, Angelo Di Iorio, Alessandro Caponi
Funded by: Alstom s.p.a., Regione Emilia Romagna, University of Bologna
Status: Ongoing.

VASTO
Keywords: Digital edition, Varchi, Storia fiorentina, EVT2, XML/TEI
Description: The digital edition of Benedetto Varchi, Storia fiorentina. An XML/TEI (diplomatic and critical) edition, with EVT2 visualization features. Proemio del Primo Libro (versione Pilot)
Researchers: Dario Brancato, Paola Italia, Francesca Tomasi
Collaborators: Milena Corbellini (DHDK graduated student), Valentina Pasqual (DHDK graduated student), Roberta Priore (PhD)
Funded by: DH.arc, University of Bologna
Release: 2020 (pilot version)
Status: Ongoing

ZERI & LODE
Keywords: Arts and Photography, Ontology Development, Linked Open Data
Description: Zeri & LODE is a project to present cataloguing data belonging to art historical photo archives by using Semantic Web technologies. It produced a number of ontologies for representing the Arts and Photography domain (OAEntry Ontology, FEntry Ontology and HiCO Ontology) and produced Linked Open Data according to the developed models.
Researchers: Marilena Daquino, Francesca Mambelli, Francesca Tomasi, Silvio Peroni, Fabio Vitali
Release: 2014
Status: Closed
Hosted Projects
UPGRADING HISTORY. DIARIES FROM THE WAR FRONT
Keywords: Diary, War, WWI, Europeana, Digital Edition EVT, TEI XML, StoryMap
Description: The project aims to reactivate and renew old personal stories of ordinary people involved in the WWI. The Europeana Collection 1914-1918 preserves a great number of diaries from the trenches: this material represents the research core. Eight diaries in French and Italian and the letters written by Isaac Rosenberg to Laurence Binyon will be processed. They are available in two versions: StoryMaps and EVT digital edition.
Researcher: Saverio Vita
Funded by: Europeana Foundation, Research Grant 2018
Release: 2018
Status: Ongoing