Corpora
Corpora developed by CoLiTec members

WaCky (Web-As-Corpus Kool Yinitiative)
A collection of large corpora built by automatically downloading texts from the web. We have made available corpora in English, French, German and Italian.
To learn more about how these corpora were created go to the WaCky website
To consult these (and other) corpora through our implementation of the noSketch Engine platform go to the Corpora at DIT page

The SiBol corpus on SketchEngine
is an English corpus made up of articles collected from various English language newspapers of the years 1993–2021. The SiBol corpus contains around 850 million words in 2 million articles (the initial version of the corpus, containing UK broadsheets, was created in 2011 and was extended in 2017 to include newspapers from other countries including India, USA, Hong Kong, Nigeria and the Arab world, as well as UK tabloids).
To learn more go to the SiBol group webiste.
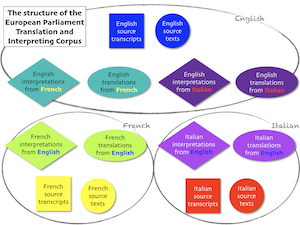
The European Parliament Interpreting and Translation Corpus (EPTIC)
EPTIC is an intermodal parallel corpus comprised of speeches delivered at the European Parliament, as well as their official interpretations and translations. The corpus has been compiled based on data collected from the official website of the European Parliament, where verbatim reports and videos of the speeches with multilingual audio tracks are made publicly available (until 2011 together with the official translations). Sub-corpora are aligned to each other at sentence level, and transcripts of speeches and interpretations are time-aligned with the corresponding videos.
Due to its unique structure, EPTIC allows its users to compare:
- interpretations and translations (in various languages)
- interpreted or translated language with non-interpreted or non-translated language
- native English with non-native English
- orthographic transcripts with video recordings
To learn more about EPTIC and consult it through our implementation of the noSketch Engine platform go to the dedicated Corpora at DIT page

EPIGRAMA
The EPIGRAMA (Spanish for Italians, Old Grammars) project makes available to the specialist the digital edition of a corpus of texts of a grammatical nature and didactic purpose published between the 16th and 19th centuries.
To learn more go to the Epigrama webiste

Serbian Twitter training corpus
and
Croatian Twitter training corpus
ReLDI-NormTagNER-sr 2.1 is a manually annotated corpus of Serbian tweets. It is meant as a gold-standard training and testing dataset for tokenisation, sentence segmentation, word normalisation, morphosyntactic tagging, lemmatisation and named entity recognition of non-standard Serbian. Each tweet is also annotated for its automatically assigned standardness levels (T = technical standardness, L = linguistic standardness).